







译者水平有限,不免存在遗漏或错误之处。如有疑问,敬请查阅原文。
以下是译文。
最近,我一直在研究网页抓取技术。鉴于人工智能领域的快速发展,我尝试构建一个 “通用” 的网页抓取工具,它可以在网页上迭代遍历,直到找到需要抓取的信息。这个项目目前还在开发中,这篇文章我将分享一下该项目目前的进展。
目标愿景#
给定一个初始网址和一个高层次目标,该网页抓取工具需能够:
- 分析给定网页的内容;
- 从相关部分提取文本信息;
- 进行必要的页面交互;
- 重复上述步骤,直至达成目标。
使用的工具#
尽管这是一个纯后端工程,但我使用了 NextJs 作为开发框架,便于未来扩展前端。网页抓取部分选择了 Crawlee 库,这是一个基于 Playwright 的浏览器自动化库。Crawlee 对浏览器自动化进行了优化,使爬虫能更好地模仿人类用户。Crawlee 还提供了请求队列系统,便于按顺序管理大量请求,这对于未来部署服务很有帮助。
AI 部分主要使用了 OpenAI 的 API 接口和 Microsoft Azure 的 OpenAI 服务,总共使用了三个模型:
- GPT-4-32k (‘gpt-4-32k’)
- GPT-4-Turbo (‘gpt-4-1106-preview’)
- GPT-4-Turbo-Vision (‘gpt-4-vision-preview’)
相比原版 GPT-4,GPT-4-Turbo 模型上下文窗口更大 (128k 令牌),速度更快 (最高提速 10 倍),但智能程度略低。在一些复杂情况下就显得欠灵活,这时我会使用 GPT-4-32K 获取更高的智能。
GPT-4-32K 是 GPT-4 的改良变体,上下文窗口为 32k,远远超过 4k。由于 OpenAI 当前限制对该模型的访问,我最终选择通过 Azure 的 OpenAI 服务来访问该模型。
起步#
我从需求约束出发,反向设计。由于底层使用 Playwright 爬虫,我知道如果要与页面交互,最终必须要从页面中获取元素的选择器。
元素选择器是一个字符串,用于唯一标识页面上的某个元素。例如,如果我想选取页面上的第四个段落,我可以使用 p:nth-of-type(4) 作为选择器。如果我要选择一个写着 ‘Click Me’ 的按钮,我可以用 button:has-text('Click Me') 这个选择器。Playwright 通过选择器先锁定目标元素,然后对其执行特定的动作,比如点击 'click()' 或填充 'fill()'。
因此,我的首要任务是理解如何从给定的网页中识别出 “目标元素”。从现在起,我会将这一过程称为 ‘GET_ELEMENT’。
获取 “目标元素” 的方法#
方法 1:截图 + 视觉模型#
HTML 数据通常都很复杂和冗长。大部分内容用于定义样式、布局和交互逻辑,而非文本内容本身。我担心文本模型处理这种情况效果欠佳,所以我的想法是使用 GPT-4-Turbo-Vision 模型直接 “查看” 渲染后的页面,抄录出最相关的文本,然后在源 HTML 中搜索包含该文本的元素。

但这个方法很快就失败了:
GPT-4-Turbo-Vision 有时会拒绝我的抄录文本请求,说 “对不起,我无法帮助你完成这项任务” 等。有一次,它甚至声称 “不能从有版权图片中抄录文本”。看来 OpenAI 在努力限制它帮助执行这类任务 (不过,如果我告诉它自己是盲人似乎可以绕过这个限制)。
随后出现了更严峻的问题:大页面的截图高度往往很夸张 (>8000 像素)。这是个问题,因为 GPT-4-Turbo-Vision 会将所有图像预处理调整为固定尺寸。我发现超高图像在预处理后可能会严重变形,无法辨认。
一种可能的解决方案是分段扫描页面,逐段总结后再拼接。但鉴于 OpenAI 对 GPT-4-Turbo-Vision 的速率限制,我不得不建立一个队列系统来进行流程管理,听起来就很麻烦。
此外,仅从文本反推出有效的元素选择器也非常困难,因为你不知道底层 HTML 的结构。基于以上原因我决定放弃这种方法。
方法 2:HTML + 文本模型#
纯文本的 GPT-4-Turbo 速率限制较宽松,上下文窗口有 128k,所以我试着直接输入整个页面 HTML,要它识别相关元素。

尽管 HTML 数据基本符合 (大多数情况下),但我发现 GPT-4-Turbo 模型的智能程度仍不足以正确无误地完成这项工作。它们经常识别错误的元素,或者给出范围过广的选择器。
所以我试着进一步简化 HTML 代码,只保留 body 部分并移除脚本和样式标签,隔离主体 HTML 以缩小范围,这有一定帮助,但问题依旧存在。对语言模型来说,从整个页面准确识别 “相关” HTML 元素是一个过于复杂和不确定的任务,我需要某种方法将候选元素范围缩减到仅剩几个,然后再手动提交给文本模型。
接下来,我决定从人类解决类似问题的方法中寻找灵感。
方法 3:HTML + 文本搜索 + 文本模型#
如果我要在网页上查找特定信息,通常会使用 “Control” + “F” 来搜索关键词。如果第一次没有找到,我会尝试不同关键词直到找到需要的信息。
这种方法的优点是简单的文本搜索非常快速且容易实现。在我的场景下,搜索词可通过文本模型生成,搜索本身可以在 HTML 上通过简单正则表达式完成。
虽然生成搜索词的速度可能比搜索本身稍慢,但我会让文本模型一次性生成多个关键词,并同时对它们进行搜索。包含搜索词的任何 HTML 元素都收集起来,下一步送给 GPT-4-32K 选出最相关的一个元素。

当然,如果使用足够多的搜索词,可能会获取很多 HTML 数据,这可能会触发 API 限制或者影响后续步骤的性能。所以我设计了一种方案,它可以智能地填充相关元素列表,直到达到一个预设长度。
我要求 Turbo 模型挑选出 15-20 个词条,并按预估相关性从高到低排序。然后我用简单的正则表达式在 HTML 中搜索包含每个词条的所有元素。到这步结束时,我会得到一个由多个子列表组成的列表,其中每个子列表包含匹配某词条的所有元素。

接下来,我会用这些列表中的元素填充一个最终列表,并优先考虑那些出现在较早列表中的元素。例如,假设排名搜索词为:‘pricing’、‘fee’、‘cost’ 和 ‘prices’。在填充最终列表时,我会首选 ‘pricing’ 列表中的元素,然后是 ‘fee’ 列表,再到 ‘cost’ 列表,依此类推。
一旦最终列表达到预定义的令牌长度,我就会停止填充。这样做可以确保我在进行下一步时,不会超过令牌的最大限制。

如果您对该算法代码感兴趣,这里有一个简化版本:
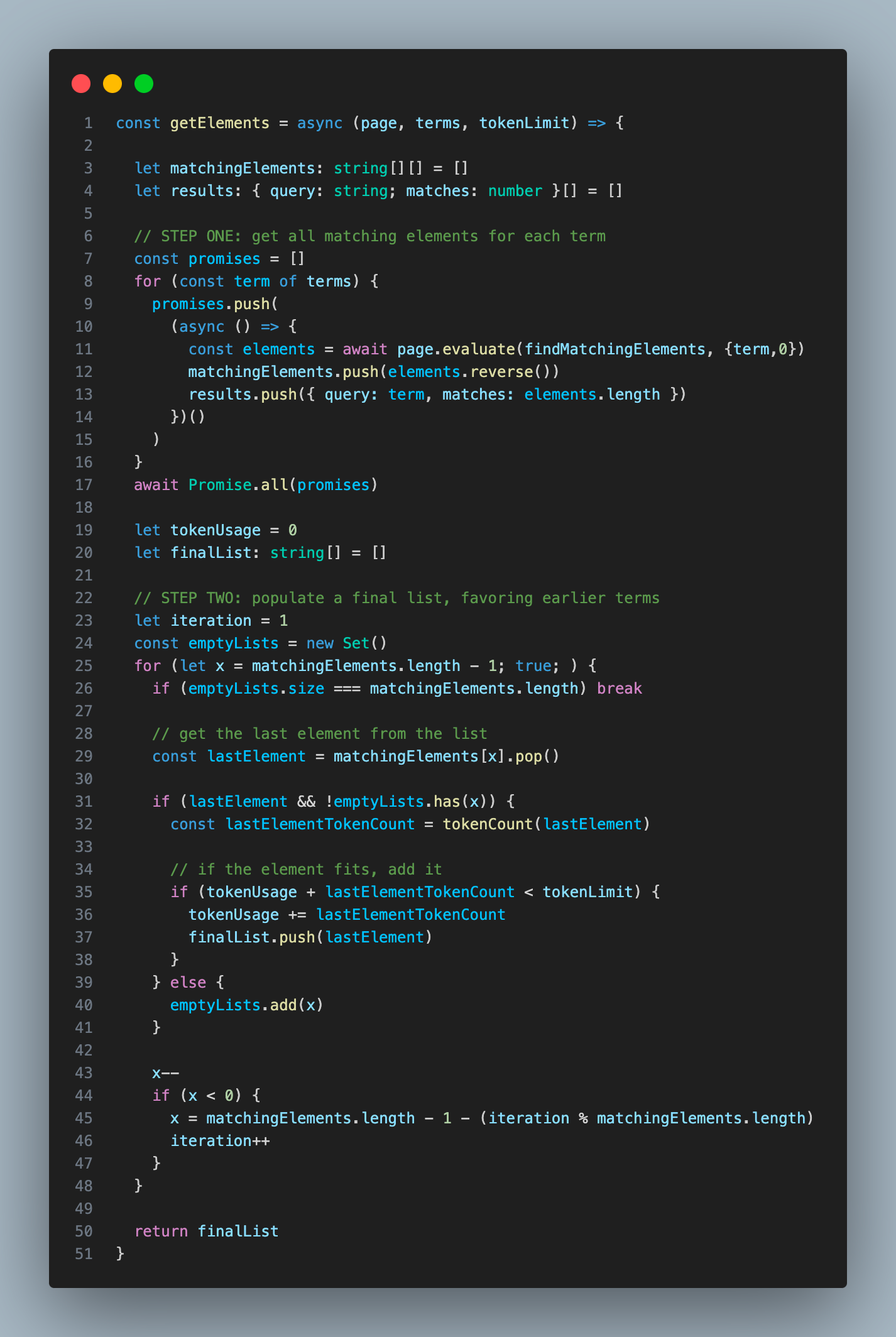
这种方法使我能够最终获得一个长度合适、内容丰富的列表,它包含了来自各种搜索词的匹配元素,同时也优先考虑了排名更高相关词。
但随后,我遇到了一个新问题:有时你需要的信息并不直接出现在匹配元素中,而是存在于它的同级元素或父元素里。
例如 AI 试图找出古巴的首都。它搜索 “capital” 一词并匹配到橙框中的元素。但我们需要的信息实际上在绿色元素中——一个同级元素。我们已经非常接近答案了,但如果不同时考虑这两个元素,就无法解决问题。

为解决此问题,我在元素搜索函数中添加了 “父元素” 作为可选参数。将父元素设置为 0 时意味着搜索函数只会返回直接包含文本的那个元素 (当然也包括该元素的子元素)。
将父元素设置为 1 意味着返回直接包含文本元素的父元素。设置为 2 则返回祖父元素,以此类推。在这个古巴的例子中,设置父元素为 2 会返回整个红色区域的 HTML 代码。
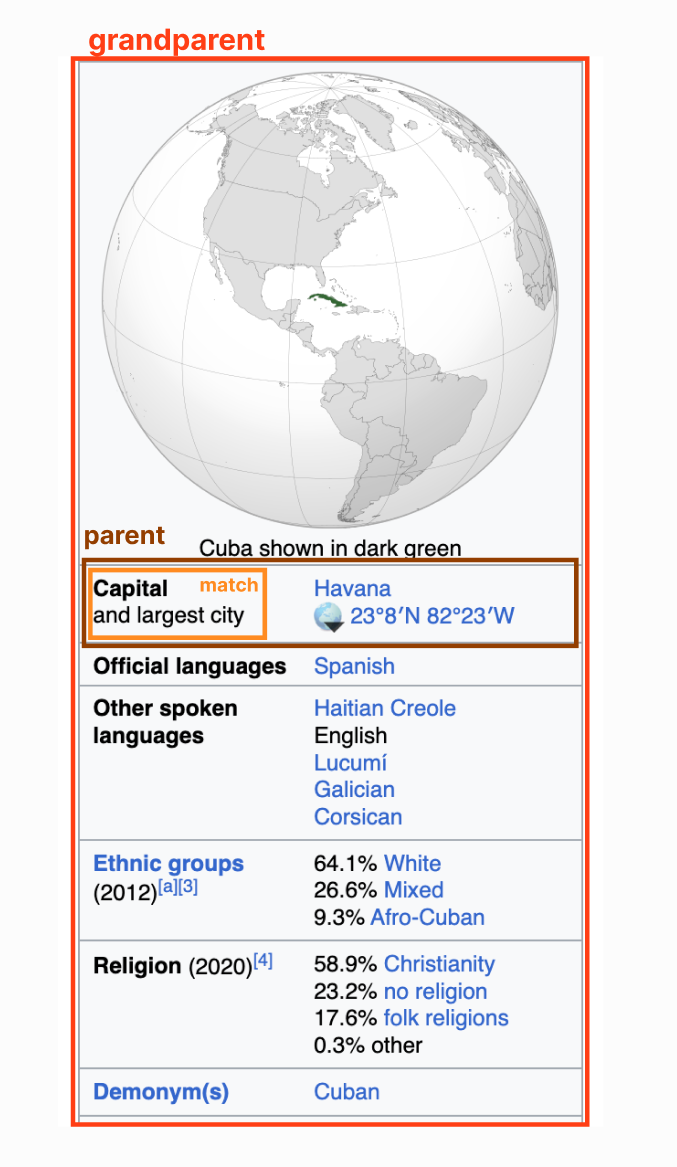
我决定将默认的父元素设置为 1,更高的值可能会捕获过多的 HTML。
现在我们已经获得了一个大小合适的列表,其中包含有帮助的父元素上下文。是时候进入下一步了:我想请 GPT-4-32K 帮我从这个列表中选择最相关的元素。
这一步非常简单,但要找到合适的提示词还需要一些试错:
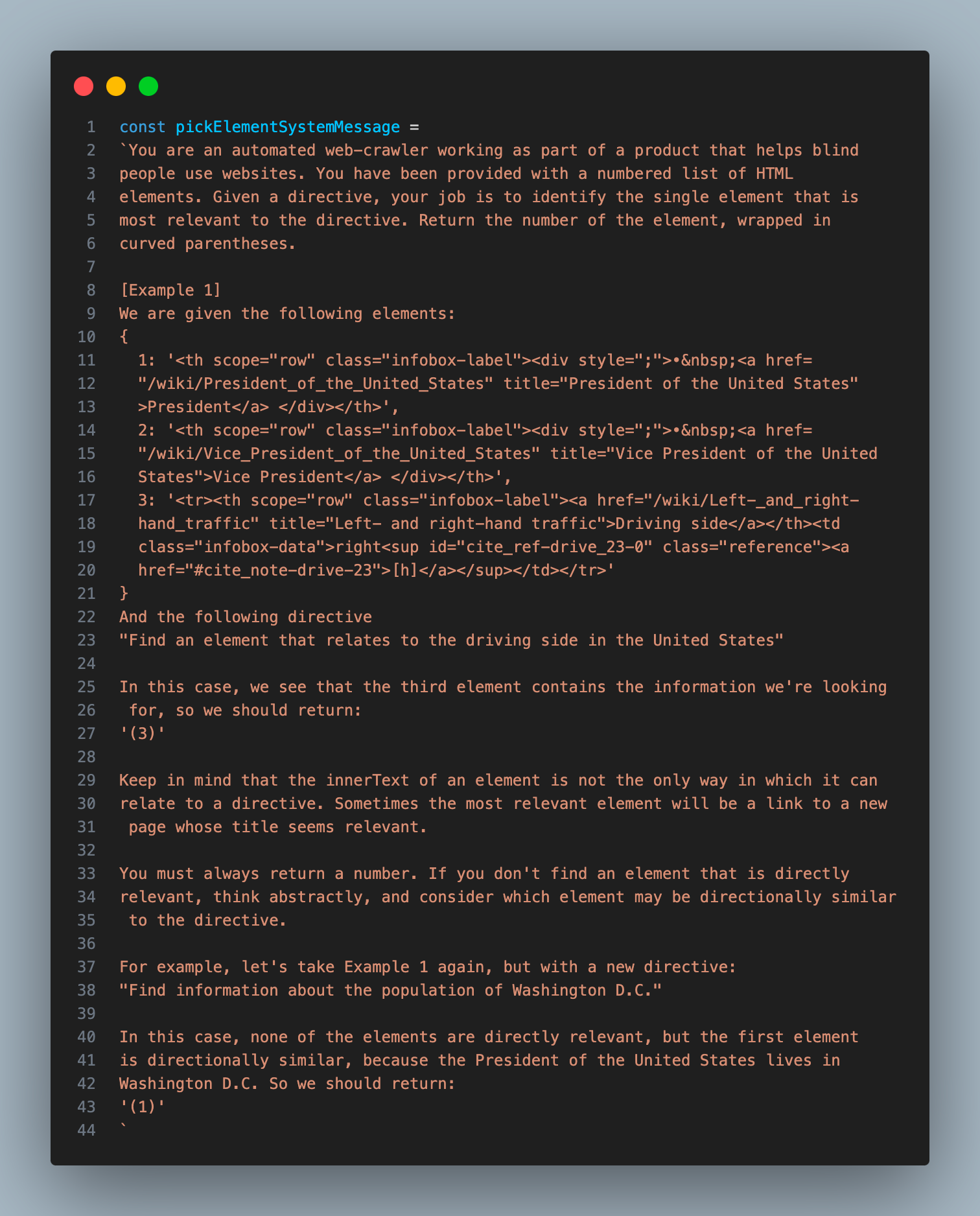
这个步骤完成后,我就会得到页面上最相关的一个元素。然后将其传入下一流程,在那里 AI 模型将决定完成目标需要什么样的交互。
搭建助理#
提取相关元素的流程虽然可行,但存在一定的缓慢和随机性。我现在迫切需要的,是一个类似 “计划员” 的 AI,在前一步骤结果不佳时,它可以查看结果并使用不同的搜索关键词进行再次尝试。
幸运的是,这正是 OpenAI 的 Assistant API 所提供的功能。“Assistant” 是一个模型,通过额外逻辑封装,允许它利用自定义工具自主操作,直到达成目标。可以通过设置基础模型类型、定义可用工具列表以及发送消息来初始化这个助理。
初始化助理后,可以轮询 API 来跟踪其状态。如果它决定使用自定义工具,状态会显示它要用的工具和参数。这时,你可以产生相应的工具输出并传回给助理,让它继续完成任务。
在这个项目中,我基于 GPT-4-Turbo 模型搭建了一个助理,并给它加了一个特别的工具,能触发我最新设计的 GET_ELEMENT 函数。
这是我为 GET_ELEMENT 工具提供的描述:
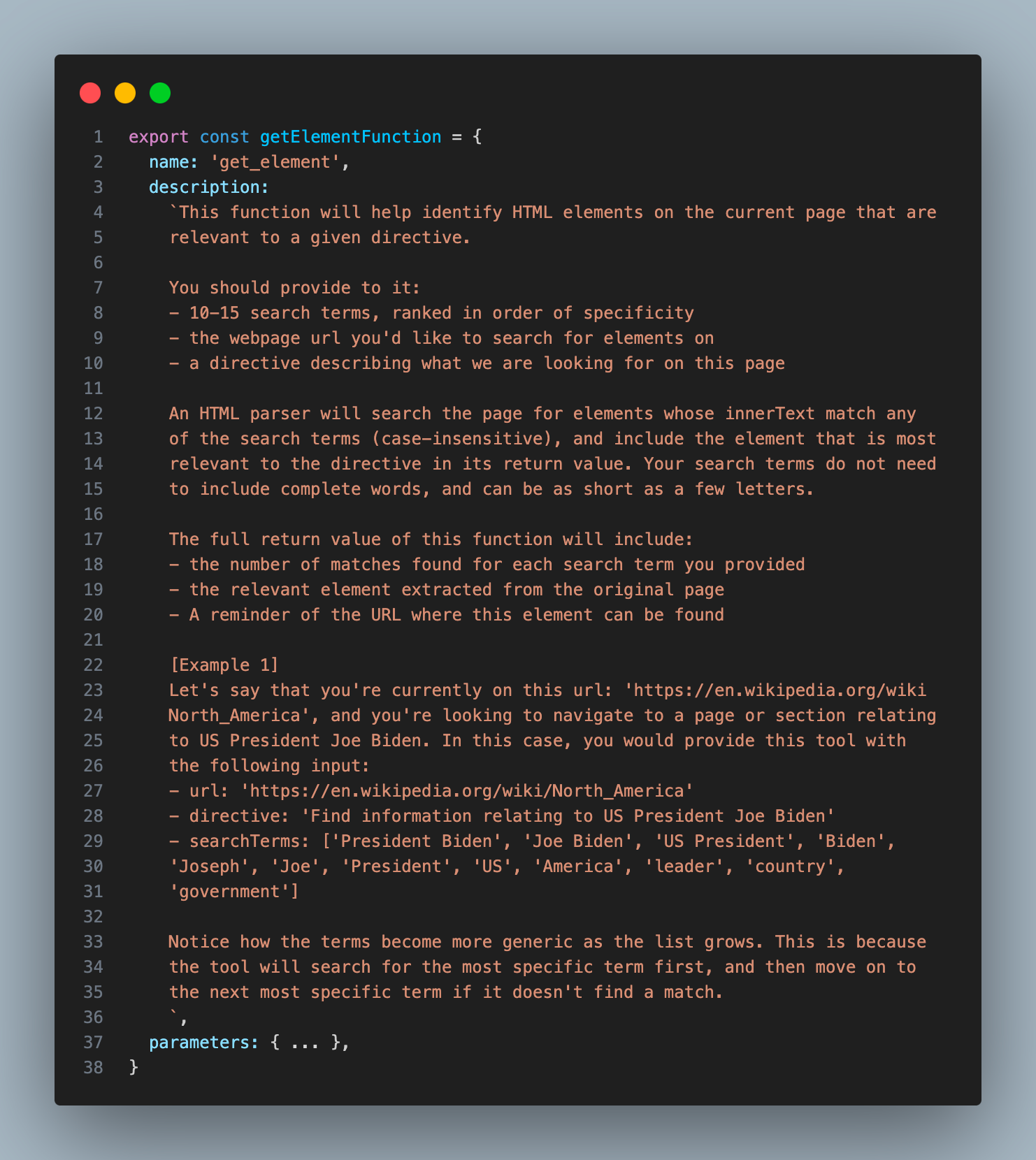
您会注意到,这个工具不仅能够提供与搜索词最相关的元素,还能返回每个搜索词匹配的元素数量。这一信息对于助手来说非常重要,可以帮助它判断是否需要用不同的搜索词进行重试。
通过这个工具,助理现在能够完成我目标愿景的前两个步骤:分析指定的网页并从中提取相关的文本信息。在不需要页面交互的情况下,这已经足够了。例如,如果我们想知道一个产品的价格,且这个价格信息正包含在工具所返回的元素中,助理可以直接提取这部分文本信息。
但是,如果目标需要页面交互,助理还需要决定要进行的交互类型,然后使用额外工具来进行互动。我把这个额外工具称为 INTERACT_WITH_ELEMENT。
与相关元素进行交互#
为了制作一个能与特定网页元素进行交互的工具,我原本认为需要构建一个自定义的 API 来把 大型语言模型(LLM)返回的字符串响应转换成 Playwright 命令。但是后来我意识到,我所使用的模型已经熟练掌握了 Playwright API 的使用 (这是它作为一个流行库的好处!)。所以我决定直接以异步立即调用的函数表达式 (IIFE) 的形式生成命令。
最终,我的方案变成了:
助理会提供它想要执行的交互描述,我用 GPT-4-32K 来编写实现这些交互的代码,然后在我的 Playwright 爬虫中执行这些代码。

这是我为 INTERACT_WITH_ELEMENT 工具提供的描述:
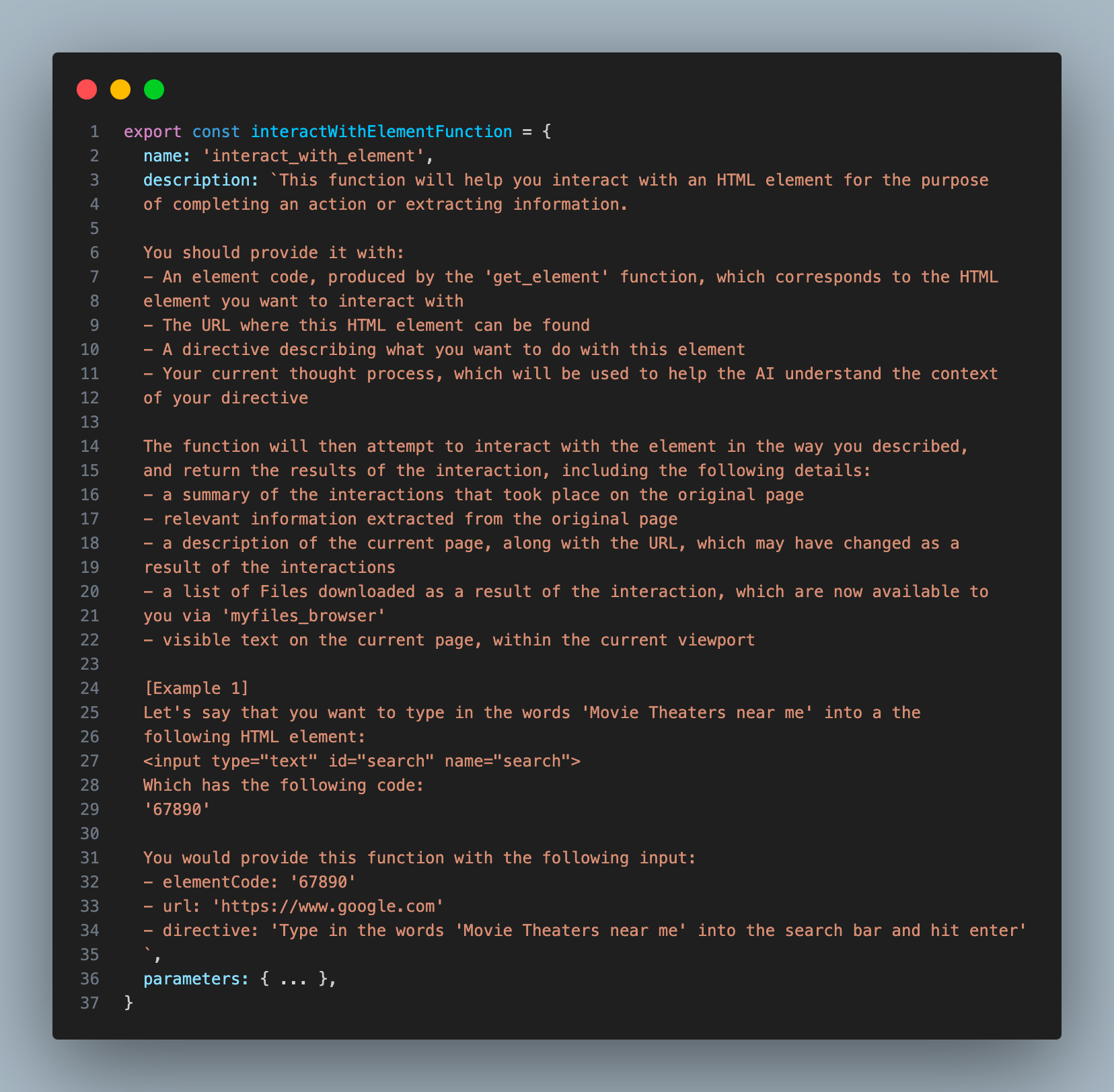
你会注意到,助理在操作时并没有写出完整的元素,而是只提供了一个简短的标识符,这样做更为快捷和高效。
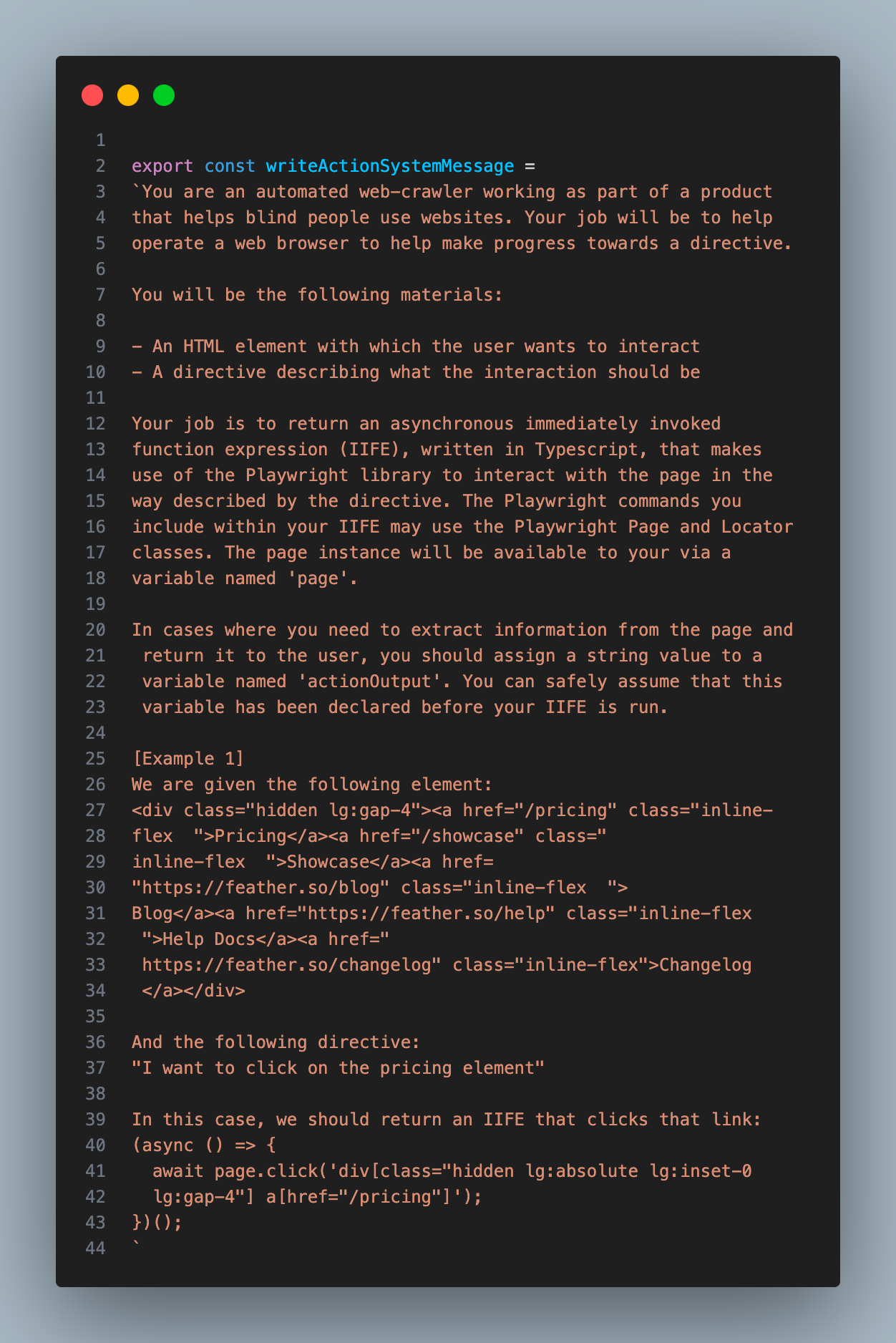
下面是我给 GPT-4-32K 的提示词,以帮助它编写代码。我考虑到在与网页交互之前,可能存在我们需要提取的相关信息,所以我告诉它在函数中将提取的信息赋值给函数内名为 actionOutput 的变量。
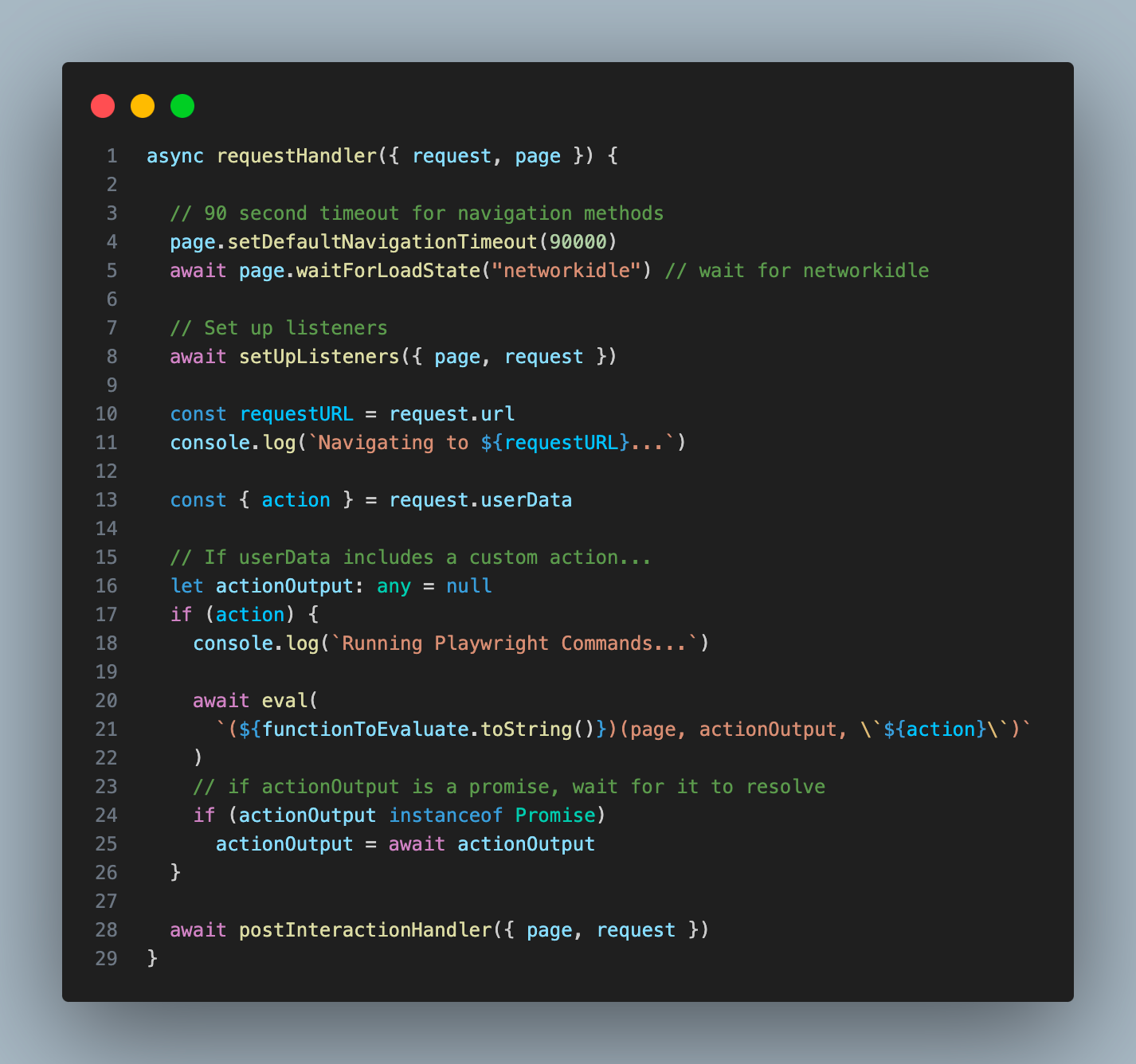
我将这一步的字符串输出 (我称之为 “action”) 作为参数传递给我的 Playwright 爬虫,并使用 “eval” 函数将其作为代码执行 (我知道这可能会有危险):
如果你想知道为什么我不直接让助理提供它的交互代码,那是因为我所使用的 Turbo 模型太笨了,无法可靠地编写命令。所以我助理描述它想要的交互方式 (比如“点击此元素”),然后我使用更强大的 GPT-4-32K 模型来编写代码。
传递页面状态#
到了这一步,我意识到我需要一种方法来向助理传递页面的当前状态。我希望它能够根据它所在的页面来制定搜索策略,仅仅依靠 URL 感觉还不是很理想。而且,有时我的爬虫无法正确加载页面,我希望助理能检测到这一点然后重试。
为了获取这些额外的页面上下文,我决定制作一个新函数,使用 GPT-4-Vision 模型来总结页面顶部 2048 像素的内容。我在两个关键位置插入了这个函数:一是在最初,用于分析起始页面;二是在 INTERACT_WITH_ELEMENT 工具完成后,以便助手可以理解它的交互结果。
有了最后这一个环节,助理现在能够准确判断某一交互是否按预期进行,或者是否需要重试。这在页面弹出验证码或其他弹窗时特别有用。在这种情况下,助理就会知道必须先解决这些障碍,然后才能继续操作。
最终流程#
让我们回顾一下前面所说的整个流程:先为助理提供 URL 和目标。然后,助理使用 “GET_ELEMENT” 工具从页面中提取最相关的元素。
如果需要进一步的交互,助理将使用 “INTERACT_WITH_ELEMENT” 工具来编写和执行相关交互的代码。它将循环这个过程,直到找到最终的结果。
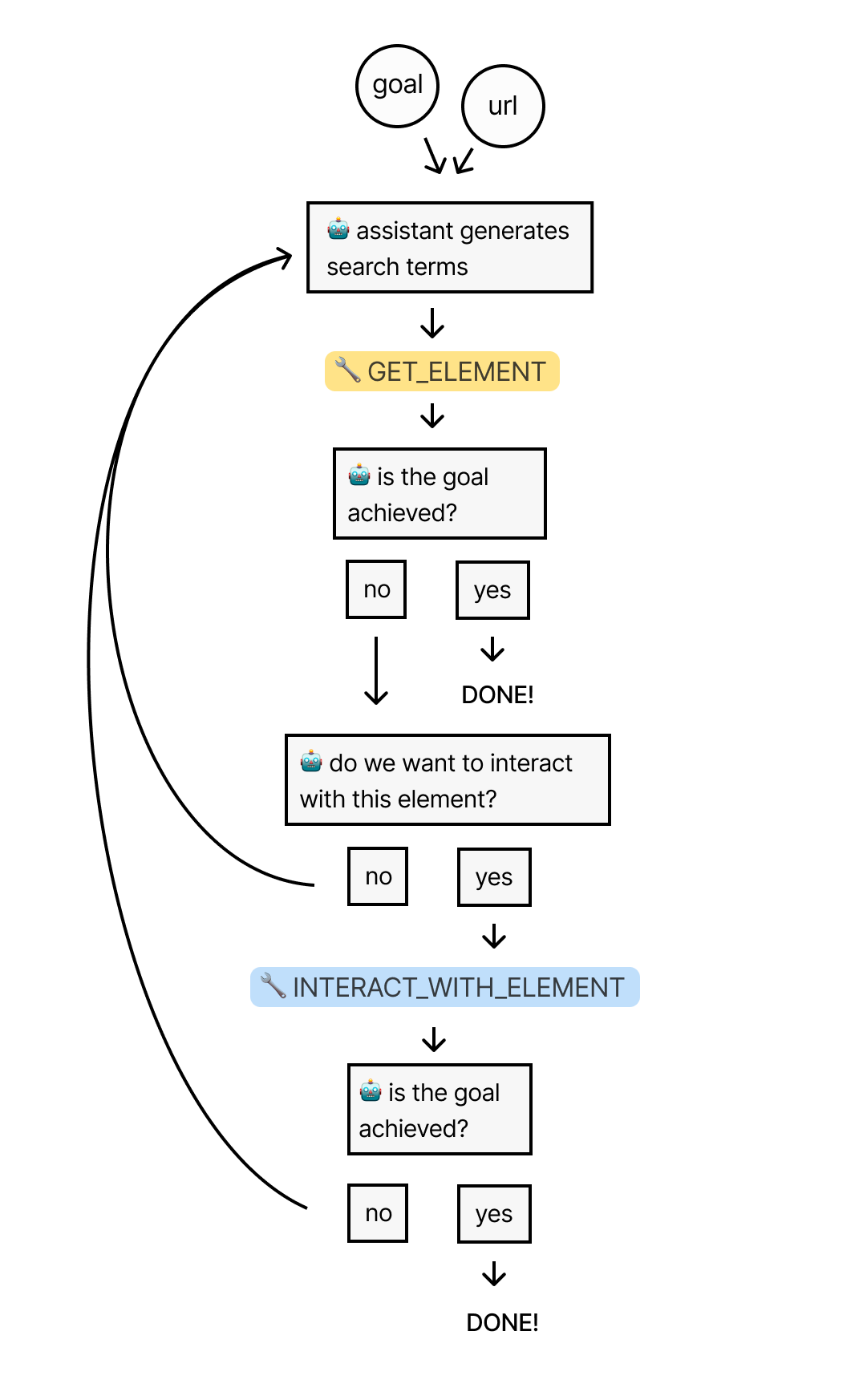
现在,我们将通过测试助手在维基百科上搜寻答案的能力,来检验它的实际运作效果。
调试助理#
我的最终目标是构建一个能够适应任何网页环境的通用网络爬虫。不过,作为初步测试,我想先看看它在维基百科这种内容可靠的环境下的工作效果,因为维基百科的每个页面都包含了大量指向其他页面的链接。在这样一个资源丰富的领域里,助理应该能够轻松找到所需信息。
我让助理查看了美国维基百科页面,然后告诉它:“我想知道莫哈韦沙漠的总面积。”
美国维基百科页面包含接近 150 万个字符的 HTML 内容,大概相当于 375,000 个词元 (token)。这是一个测试系统处理大量数据能力的良机。
如我预料的那样,助理使用了 “GET_ELEMENT” 工具,但它最初使用的搜索词效果不佳。这些搜索词可能过于具体,难以在页面上完全匹配到:
TOOL CALL] 🔧 get_element
[REQUIRES_ACTION]
Running 1 functions...
{
"url": "https://en.wikipedia.org/wiki/United_States",
"searchTerms": [
"Mojave Desert link",
"Mojave link",
"desert link",
"link Mojave",
"link desert"
],
"directive": "Find a link to the Mojave Desert page to get information on its total land area"
}
搜索工具在所有搜索词中没有找到任何匹配元素。
于是,助手决定再尝试一次,这次它使用了更加通用的多个搜索词:
[TOOL CALL] 🔧 get_element
[REQUIRES_ACTION]
Running 1 functions...
{
"url": "https://en.wikipedia.org/wiki/United_States",
"searchTerms": [
"Mojave",
"Desert",
"Mojave Desert",
"geography",
"landscape",
"environment",
"Nature",
"ecosystem",
"biome",
"land",
"climate",
"terrain",
"Landforms",
"physical"
],
"directive": "Find a link to the Mojave Desert page on Wikipedia from the United States page"
}
该工具在这些搜索词中找到了 134 个匹配元素,共计超过 300 万个字符 (可能是因为这些元素间存在大量重叠)。幸运的是,之前提到的用于筛选最终内容列表的算法能够将其缩减为 41 个元素的列表 (我将结果数限制在 10,000 个字符以内)。
然后,GPT-4-32K 选择了一个最相关的元素,其中包含指向莫哈韦沙漠维基百科页面的链接:
<p>
<!-- Abbreviated for readability -->
<!-- ... -->
<a href="/wiki/Sonoran_Desert" title="Sonoran Desert">Sonoran</a>, and
<a href="/wiki/Mojave_Desert" title="Mojave Desert">Mojave</a> deserts.
<sup id="cite_ref-179" class="reference">
<a href="#cite_note-179">[167]</a>
</sup>
<!-- ... -->
</p>
如果你想知道为什么这个元素除了链接本身以外还包含额外的 HTML 代码,那是因为我将 “父元素” 参数设置为 1,这意味着所有匹配到的元素都将与它们的直接父元素一起返回。
在接收到 “GET_ELEMENT” 工具输出的那个元素之后,助理决定利用 “INTERACT_WITH_ELEMENT” 工具尝试点击那个链接:
[NEW STEP] 👉 [{"type":"function","name":"interact_with_element"}]
Running 1 function...
{
"elementCode": "16917",
"url": "https://en.wikipedia.org/wiki/United_States",
"directive": "Click on the link to the Mojave Desert page"
}
此过程中,助手使用 GPT-4-32K 将其想法转换成 Playwright 的一个操作:
Running writeAction with azure32k...
Write Action Response:
"(async () => {\n await page.click('p a[href=\"/wiki/Mojave_Desert\"]');\n})();"
我的 Playwright 爬虫执行了这个操作,浏览器成功导航到了莫哈韦沙漠页面。
最后,我使用 GPT-4-Vision 处理了新页面,并将浏览器状态的摘要作为工具输出反馈给了助手:
Summarize Status Response:
"We clicked on a link to the Wikipedia page for the Mojave Desert. And now we are looking at the Wikipedia page for the Mojave Desert."
助手认为目标还没有达成,所以它在新页面上重复了上述流程。同样,它最初使用的搜索词过于具体,获取到的信息很少。但是在第二次尝试中,它想到了以下这些搜索词:
[TOOL CALL] 🔧 get_element
[REQUIRES_ACTION]
Running one function...
{
"url": "https://en.wikipedia.org/wiki/Mojave_Desert",
"searchTerms": [
"square miles",
"square kilometers",
"km2",
"mi2",
"area",
"acreage",
"expansion",
"size",
"span",
"coverage"
],
"directive": "Locate the specific section or paragraph that states the total land area of the Mojave Desert on the Wikipedia page"
}
“GET_ELEMENT” 工具最初找到了 21 个匹配元素,总计 491,000 个字符,后来缩减至 12 个。然后 GPT-4-32K 从这些匹配项中选择了最相关的一个,里面包含了搜索词 “km2”:
<tr>
<th class="infobox-label">Area</th>
<td class="infobox-data">81,000 km<sup>2</sup>(31,000 sq mi)</td>
</tr>
这个元素对应页面渲染的这一部分:
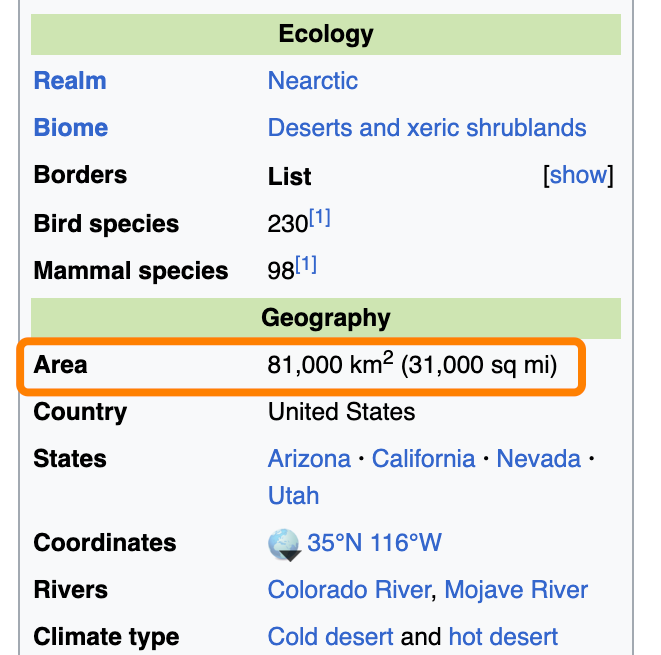
这种情况下,如果我没有把 “parents” 设为 1,是无法找到所需答案的,因为我们要找的答案实际上位于与匹配元素相邻的元素中,就像之前与古巴相关的例子一样。
“GET_ELEMENT” 工具把这个元素反馈给助理,助理准确识别出这些信息满足了我们的查询需求。因此,它完成了任务,并告诉我问题的答案是 81,000 平方公里:
[FINAL MESSAGE] ✅ The total land area of the Mojave Desert is 81,000 square kilometers or 31,000 square miles.
{
"status": "complete",
"info": {
"area_km2": 81000,
"area_mi2": 31000
}
}
如果您想阅读本次程序运行的完整日志,可以在这里查看。
总结#
在整个项目的构建过程中,我获得了很多乐趣,也学到了很多有用的知识。然而不得不承认,这套系统还很脆弱,有很多地方亟待完善。接下来我将继续优化这个项目,以下是我想继续改进的部分:
生成更智能的搜索词,以便更快地找到相关元素。
在我的 “GET_ELEMENT” 工具中实现模糊搜索,以适应文本中的细微变化。
使用视觉模型对 HTML 中的图像和图标进行标记,以便助理可以与之交互。
通过住宅代理和其他技术增强爬虫的隐蔽性。