







该系列文章总共分为三篇:
通过上篇文章的学习,我们学会了如何查看当前 cgroup 的信息,如何通过操作 /sys/fs/cgroup 目录来动态设置 cgroup,也学会了如何设置 CPU shares 和 CPU quota 来控制 slice 内部以及不同 slice 之间的 CPU 使用时间。本文将把重心转移到内存上,通过具体的示例来演示如何通过 cgroup 来限制内存的使用。
寻找走失内存#
上篇文章告诉我们,CPU controller 提供了两种方法来限制 CPU 使用时间,其中 CPUShares 用来设置相对权重,CPUQuota 用来限制 user、service 或 VM 的 CPU 使用时间百分比。例如:如果一个 user 同时设置了 CPUShares 和 CPUQuota,假设 CPUQuota 设置成 50%,那么在该 user 的 CPU 使用量达到 50% 之前,可以一直按照 CPUShares 的设置来使用 CPU。
对于内存而言,在 CentOS 7 中,systemd 已经帮我们将 memory 绑定到了 /sys/fs/cgroup/memory。systemd 只提供了一个参数 MemoryLimit 来对其进行控制,该参数表示某个 user 或 service 所能使用的物理内存总量。拿之前的用户 tom 举例, 它的 UID 是 1000,可以通过以下命令来设置:
$ systemctl set-property user-1000.slice MemoryLimit=200M
现在使用用户 tom 登录该系统,通过 stress 命令产生 8 个子进程,每个进程分配 256M 内存:
$ stress --vm 8 --vm-bytes 256M
按照预想,stress 进程的内存使用量已经超出了限制,此时应该会触发 oom-killer,但实际上进程仍在运行,这是为什么呢?我们来看一下目前占用的内存:
$ cd /sys/fs/cgroup/memory/user.slice/user-1000.slice
$ cat memory.usage_in_bytes
209661952
奇怪,占用的内存还不到 200M,剩下的内存都跑哪去了呢?别慌,你是否还记得 linux 系统中的内存使用除了包括物理内存,还包括交换分区,也就是 swap,我们来看看是不是 swap 搞的鬼。先停止刚刚的 stress 进程,稍等 30 秒,观察一下 swap 空间的占用情况:
$ free -h
total used free shared buff/cache available
Mem: 3.7G 180M 3.2G 8.9M 318M 3.3G
Swap: 3.9G 512K 3.9G
重新运行 stress 进程:
$ stress --vm 8 --vm-bytes 256M
查看内存使用情况:
$ cat memory.usage_in_bytes
209637376
发现内存占用刚好在 200M 以内。再看 swap 空间占用情况:
$ free
total used free shared buff/cache available
Mem: 3880876 407464 3145260 9164 328152 3220164
Swap: 4063228 2031360 2031868
和刚刚相比,多了 2031360-512=2030848k,现在基本上可以确定当进程的使用量达到限制时,内核会尝试将物理内存中的数据移动到 swap 空间中,从而让内存分配成功。我们可以精确计算出 tom 用户使用的物理内存+交换空间总量,首先需要分别查看 tom 用户的物理内存和交换空间使用量:
$ egrep "swap|rss" memory.stat
rss 209637376
rss_huge 0
swap 1938804736
total_rss 209637376
total_rss_huge 0
total_swap 1938804736
可以看到物理内存使用量为 209637376 字节,swap 空间使用量为 1938804736 字节,总量为 (209637376+1938804736)/1024/1024=2048 M。而 stress 进程需要的内存总量为 256*8=2048 M,两者相等。
这个时候如果你每隔几秒就查看一次 memory.failcnt 文件,就会发现这个文件里面的数值一直在增长:
$ cat memory.failcnt
59390293
从上面的结果可以看出,当物理内存不够时,就会触发 memory.failcnt 里面的数量加 1,但此时进程不一定会被杀死,内核会尽量将物理内存中的数据移动到 swap 空间中。
关闭 swap#
为了更好地观察 cgroup 对内存的控制,我们可以用户 tom 不使用 swap 空间,实现方法有以下几种:
将
memory.swappiness文件的值修改为 0:$ echo 0 > /sys/fs/cgroup/memory/user.slice/user-1000.slice/memory.swappiness这样设置完成之后,即使系统开启了交换空间,当前 cgroup 也不会使用交换空间。
直接关闭系统的交换空间:
$ swapoff -a如果想永久生效,还要注释掉
/etc/fstab文件中的 swap。
如果你既不想关闭系统的交换空间,又想让 tom 不使用 swap 空间,上面给出的第一个方法是有问题的:
- 你只能在 tom 用户登录的时候修改
memory.swappiness文件的值,因为如果 tom 用户没有登录,当前的 cgroup 就会消失。 - 即使你修改了
memory.swappiness文件的值,也会在重新登录后失效
如果按照常规思路去解决这个问题,可能会非常棘手,我们可以另辟蹊径,从 PAM 入手。
Linux PAM(Pluggable Authentication Modules) 是一个系统级用户认证框架,PAM 将程序开发与认证方式进行分离,程序在运行时调用附加的“认证”模块完成自己的工作。本地系统管理员通过配置选择要使用哪些认证模块,其中 /etc/pam.d/ 目录专门用于存放 PAM 配置,用于为具体的应用程序设置独立的认证方式。例如,在用户通过 ssh 登录时,将会加载 /etc/pam.d/sshd 里面的策略。
从 /etc/pam.d/sshd 入手,我们可以先创建一个 shell 脚本:
$ cat /usr/local/bin/tom-noswap.sh
#!/bin/bash
if [ $PAM_USER == 'tom' ]
then
echo 0 > /sys/fs/cgroup/memory/user.slice/user-1000.slice/memory.swappiness
fi
然后在 /etc/pam.d/sshd 中通过 pam_exec 调用该脚本,在 /etc/pam.d/sshd 的末尾添加一行,内容如下:
$ session optional pam_exec.so seteuid /usr/local/bin/tom-noswap.sh
现在再使用 tom 用户登录,就会发现 memory.swappiness 的值变成了 0。
systemctl set-property user-1000.slice MemoryLimit=200M 命令设置了 limit,/sys/fs/cgroup/memory/user.slice/user-1000.slice 目录才会存在。所以上面的所有操作,一定要保证至少保留一个用户 tom 的登录会话。控制内存使用#
关闭了 swap 之后,我们就可以严格控制进程的内存使用量了。还是使用开头提到的例子,使用用户 tom 登录该系统,先在第一个 shell 窗口运行以下命令:
$ journalctl -f
打开第二个 shell 窗口(还是 tom 用户),通过 stress 命令产生 8 个子进程,每个进程分配 256M 内存:
$ stress --vm 8 --vm-bytes 256M
stress: info: [30150] dispatching hogs: 0 cpu, 0 io, 8 vm, 0 hdd
stress: FAIL: [30150] (415) <-- worker 30152 got signal 9
stress: WARN: [30150] (417) stress: FAIL: [30150] (415) <-- worker 30151 got signal 9
stress: WARN: [30150] (417) now reaping child worker processes
stress: FAIL: [30150] (415) <-- worker 30154 got signal 9
stress: WARN: [30150] (417) now reaping child worker processes
stress: FAIL: [30150] (415) <-- worker 30157 got signal 9
stress: WARN: [30150] (417) now reaping child worker processes
stress: FAIL: [30150] (415) <-- worker 30158 got signal 9
stress: WARN: [30150] (417) now reaping child worker processes
stress: FAIL: [30150] (451) failed run completed in 0s
现在可以看到 stress 进程很快被 kill 掉了,回到第一个 shell 窗口,会输出以下信息:
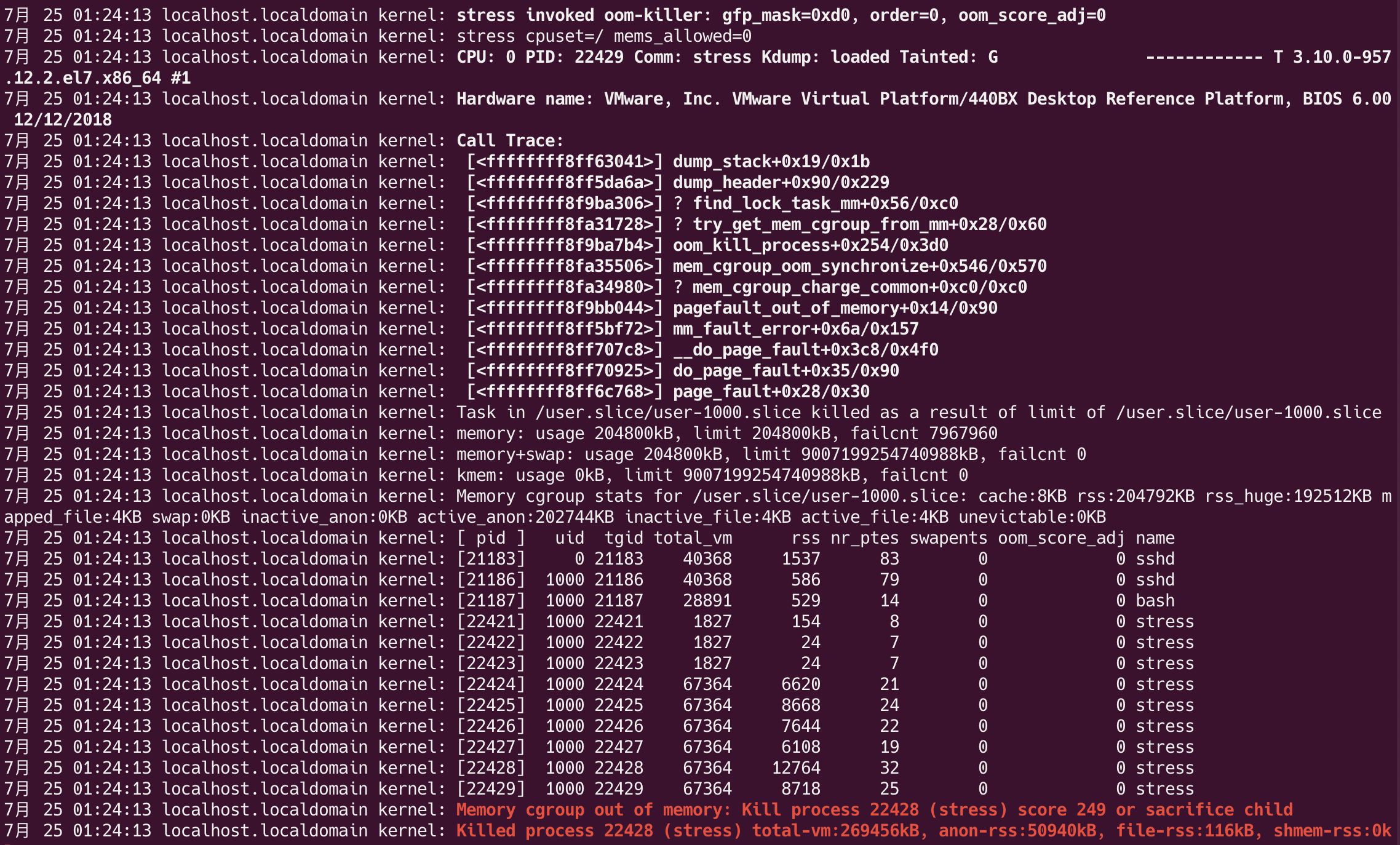
由此可见 cgroup 对内存的限制奏效了,stress 进程的内存使用量超出了限制,触发了 oom-killer,进而杀死进程。
更多文档#
加个小插曲,如果你想获取更多关于 cgroup 的文档,可以通过 yum 安装 kernel-doc 包。安装完成后,你就可以进入 /usr/share/docs 的子目录,查看每个 cgroup controller 的详细文档。
$ cd /usr/share/doc/kernel-doc-3.10.0/Documentation/cgroups
$ ll
总用量 172
4 -r--r--r-- 1 root root 918 6月 14 02:29 00-INDEX
16 -r--r--r-- 1 root root 16355 6月 14 02:29 blkio-controller.txt
28 -r--r--r-- 1 root root 27027 6月 14 02:29 cgroups.txt
4 -r--r--r-- 1 root root 1972 6月 14 02:29 cpuacct.txt
40 -r--r--r-- 1 root root 37225 6月 14 02:29 cpusets.txt
8 -r--r--r-- 1 root root 4370 6月 14 02:29 devices.txt
8 -r--r--r-- 1 root root 4908 6月 14 02:29 freezer-subsystem.txt
4 -r--r--r-- 1 root root 1714 6月 14 02:29 hugetlb.txt
16 -r--r--r-- 1 root root 14124 6月 14 02:29 memcg_test.txt
36 -r--r--r-- 1 root root 36415 6月 14 02:29 memory.txt
4 -r--r--r-- 1 root root 1267 6月 14 02:29 net_cls.txt
4 -r--r--r-- 1 root root 2513 6月 14 02:29 net_prio.txt
下一篇文章将会讨论如何使用 cgroup 来限制 I/O,敬请期待~